My headline is an exaggeration, but only a slight one. Bear with me:
Last night at about 11PM there were two armed robberies on campus in quick succession. (Nobody was hurt, thankfully!) UNC has an elaborate campus alert system called Alert Carolina designed for just such an occasion. The sirens went off as intended. The accompanying email and text message blast did not.
It wasn’t until 11:45PM that a message with details was finally sent, by which point the crisis was essentially over. The All Clear siren sounded at midnight. (The Daily Tar Heel has a more complete timeline)
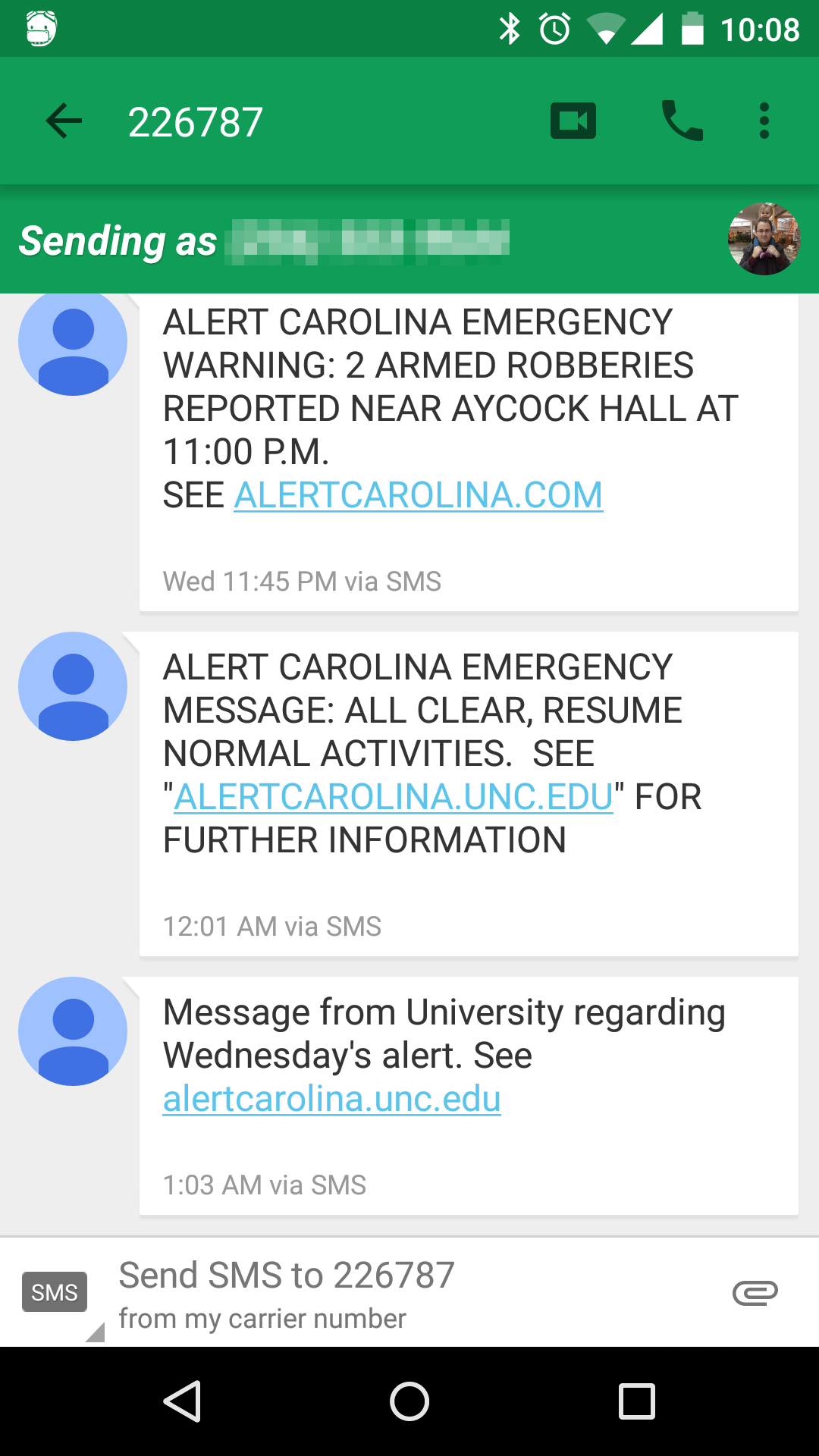
Text messages sent by Alert Carolina. Note the incorrect URL in the topmost message.
But here’s what is, from the perspective of my work, extra shameful: even when that text message finally went out, it had the wrong URL listed for more information. Instead of alertcarolina.unc.edu, it pointed to alertcarolina.com. That .com is held by a domain squatter, and helpfully offers hotel deals. While follow-up messages had the correct URL, none of them acknowledged the initial error. In fact, even the official statement about the delayed message still doesn’t mention the incorrect URL.
So what can we learn from this? While I have great sympathy for staff who work what I assume is likely a finicky but powerful piece of software like Alert Carolina, why didn’t they have a clear content management strategy in place for an event like this? The official statement calls this a “breakdown in communication”, but doesn’t elaborate. While an unpredictable event like this can only be planned for so much, it would be easy to build in simple structures in advance to help manage a crisis:
- Have content templates ready to go for emergency updates. This would avoid the incorrect URL problem while still allowing flexibility to communicate as needed. At UNC Libraries we have templates ready to go for when we quickly close due to weather, for example.
- Have clearly written backup procedures for when a mission critical system fails. These should cover both technical and personnel issues. There are countless campus listservs that could have been used to send a backup notification during those 45 minutes, for example. Or (I’m speculating) maybe nobody was at work who knew how to trigger the alert messages. Staffing redundancy should be built in for something at this level of importance. Build sanity checks into your procedures too, defined review points where someone looks to see if everything’s on course.
- If something does go wrong, immediately be transparent and open about what happened and what you’ll do to fix it. The vague “breakdown in communication” acknowledgement is not sufficient in this case. Right now I don’t trust Alert Carolina to function in the next emergency situation.
Most of this can be boiled down to: Know who is responsible for which content, and prepare for as many eventualities as you can in advance. “Content strategy plans for the creation, publication, and governance of useful, usable content.” That’s it in a nutshell, and in this case Alert Carolina unfortunately makes for a great case study.
I’m lucky – the content I deal with on a daily basis isn’t a life and death matter. But that doesn’t mean I can’t have the same level of readiness, at least on a basic level.