
Background
Library.unc.edu last received a comprehensive overhaul in 2013. Since then, the Libraries as an organization have substantially changed. A new site needs to serve as a front door to a unified, one library set of services, resources, and collections. The Libraries have a large amount of legacy web content, some of it almost as old as the web itself, which presents unique challenges in moving forward. I’m leading the team working on this overhaul, with an estimated completion of December 2023.
This work notably includes merging the UNC Libraries’ website with the UNC Health Sciences Library’s website.
Process
We began with a full information architecture audit of both major sites and examples of legacy content. We looked at published pages and asked ourselves about currency, responsibility, and types of content.
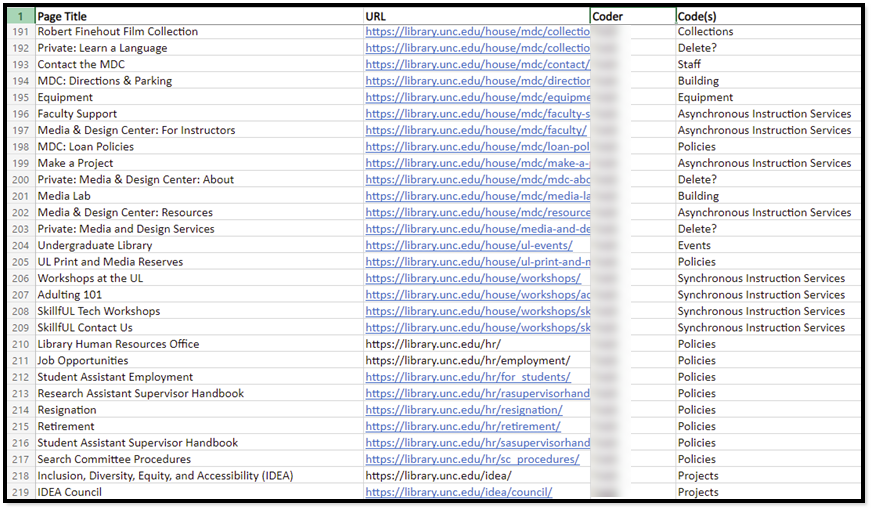
Next, we grouped content by like types.
Alongside this, we reviewed over 8,000 site searches by hand to gain understanding into what users come to our site for. We also interviewed internal stakeholders about their requirements for web content.
We found lots of common threads in our content, repeated elements that follow similar formats to each other. We started thinking about content in a fundamentally different way – at the item level, not at the page level. For example, our instruction services shouldn’t be a collection of static pages. They should be represented in a list of services, searchable and filterable by instructors looking for classroom assistance.
We’ve iterated on and validated that item-level architecture through user research. And today we’re working on implementing it. We’ve partnered with designers to bring it to life, and will continue to iterate based on research and feedback until launch.
My Roles & Methods
- Project Manager
- Content audit data processing
- Card Sorts
- Optimal Workshop’s Treejack for validating architectures